Enter The Demon Zone
Intentional and Unintentional Machine Learning Failures
For the past few months, I've been working with machine learning and intentionally overfitting/breaking models. This is very much a work in progress, but is an attempt to explain why I think these phenomena are so interesting. I welcome your feedback as I continue to work through these ideas.
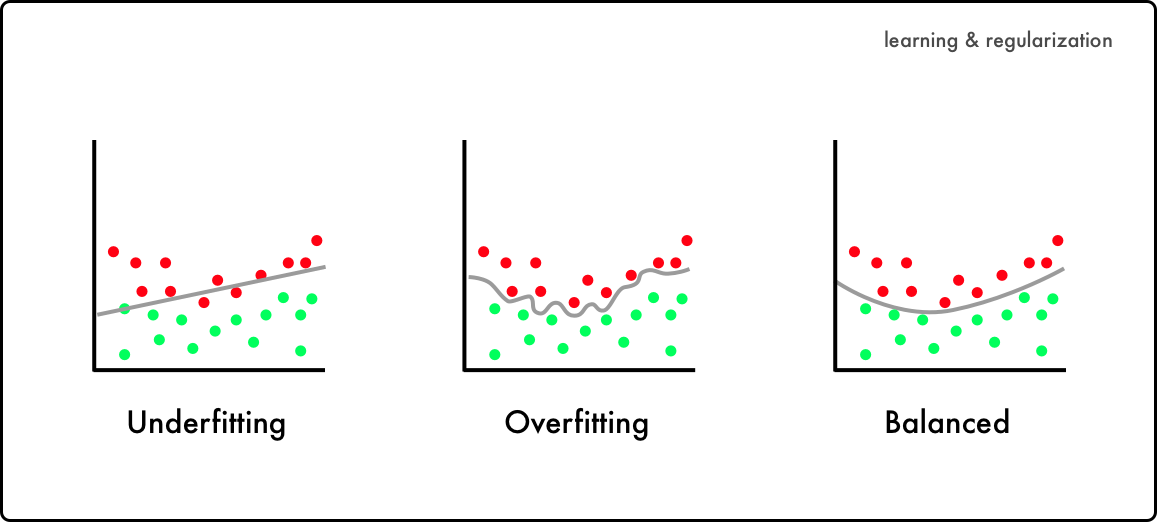
Overfitting is a well-documented phenomenon in machine learning, and one widely considered to be undesirable. It's what occurs when your model works too well, when it can perform perfectly on a training set but can't respond to new data. This can often result from a too-small dataset - a lack of diversity of examples results in the model learning only to replicate what it's been trained on. Imagine a generative text model trained on Moby Dick that can only regurgitate text directly from its source, instead of wacky commentary about Donald Trump in the tone of Herman Melville. That's peak overfitting, and I'm inclined to agree that it's not a terribly interesting or useful outcome.
But there are many degrees of overfitting. When training or finetuning a text model, especially on a small dataset, you may find it reach the point where, while it's not necessarily directly quoting its source text, it doesn't know what to do. It will repeat itself over and over, trying to draw something novel from its limited source. This is where overfitting can become an interesting phenomenon. Repetition and nonsense are long-respected methods in art practice, and we ignore their value in machine learning outcomes at our own peril.

A similar problem that can arise specifically in GANS, or generative adversarial networks (though they're less in vogue these days with the rise of diffusion models like Dall-E and Stable Diffusion) is quality collapse. The model, consisting of a generator and a discriminator, is basically trying to get good enough at faking an image from its training set that the discriminator isn't sure if it's a real image or not. But, the better the generator gets, the less valuable the discriminator's input becomes. Once the discriminator is only right about 50% of the time, the generator, as far as it can tell, has done its job, and if you continue training it the results can become "junk data". On models of people, or faces, this often manifests as nightmare creatures or blobs like Tetsuo at the end of Akira.
{kind=link}
Once again, though, these outcomes are not always undesirable, especially when you reach the liminal zone between a coherent outcome and noise. Any fan of Cronenberg, H.R. Giger, or droopy eyes will tell you that these nightmare outcomes can be beautiful.
I am not a data scientist, nor am I even a particularly good programmer. However, it seems to me that we're too quick to dismiss models that result in these outcomes. There is treasure to be found in the latent space of nonsense and nightmares, when the mode collapses and the model enters what I call The Demon Zone.
Learning To Love Your Limits
Recently I've been exploring the hellscape of LinkedIn. My inital goal, as my previous post lays out, was a classic machine learning one: make a model that can successfully create convincing, novel data. In this case, that outcome was to be a potential Meta employee. But I quickly ran into a major technical hurdle: LinkedIn really doesn't want people to scrape it.
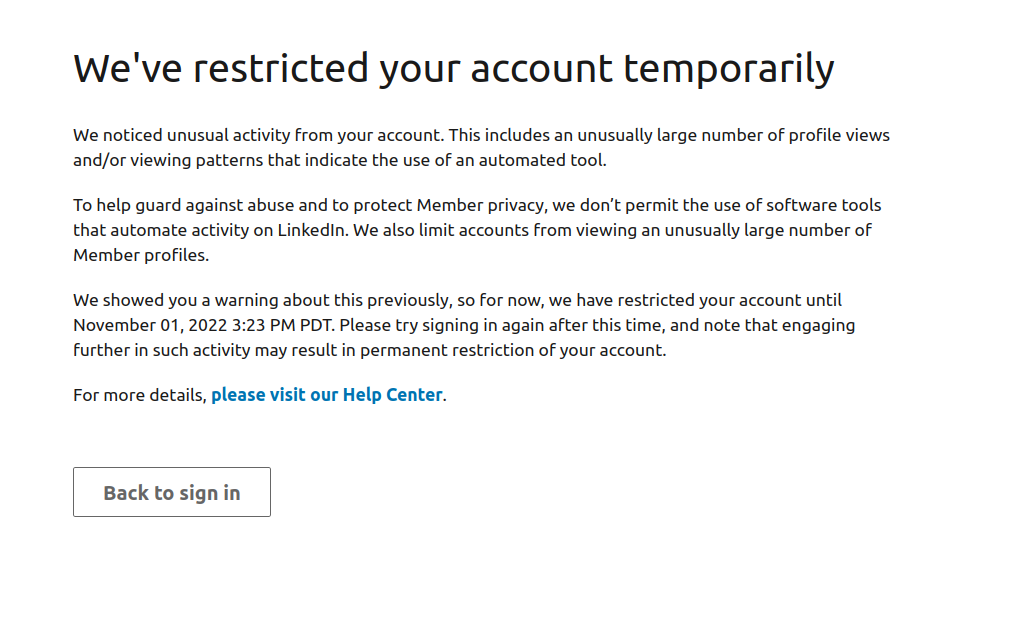
Faced with this problem, I found myself stuck with what meager data I could get on my own - a few dozen profiles' worth. But, as Orson Welles once said, the absence of limitations is the enemy of art. I decided to take my limited data and see what I could accomplish.
I began by finetuning GPT-2, another out-of-date model, but an easy one to set up, on the profiles I'd gathered. With such a small dataset, I knew I wouldn't want to spend much time training, or the model would overfit. So I ran it for a few iterations and got a reasonably good outcome:

This reads, at least sort of, like a real person's bio. Mission accomplished. But, frankly, it isn't doing much for me. Sure, I could maybe make a convincing LinkedIn profile with the model I had, but I wasn't going to get through any interviews. I'd need more data for that.

So, instead, I decided to see what happened if I kept on training. The model began to overfit, but I was suddenly much more enthralled by its outcome than I had been.

There's something beautiful about the monotony of this outcome. It's a desperate cry to seem normal and employable. So I kept going.
And ultimately, I reached the truth.

By overfitting the model, I had discovered something that felt more true than any fake person could. If LinkedIn is where we go to perform our labor, this model had become its ideal self: repeating, endlessly, how proud it is to work at Meta. A model meant to become man had become demon.
So I tried the same thing on images, using StyleGAN3. The first few iterations, again, made some real-seeming fake people.

But once again, I kept going.

And eventually, we began to enter the Demon Zone.

My nightmare complete, I began to combine the two, resulting in a digital home for the demon zone.
The Human-Machine Feedback Loop
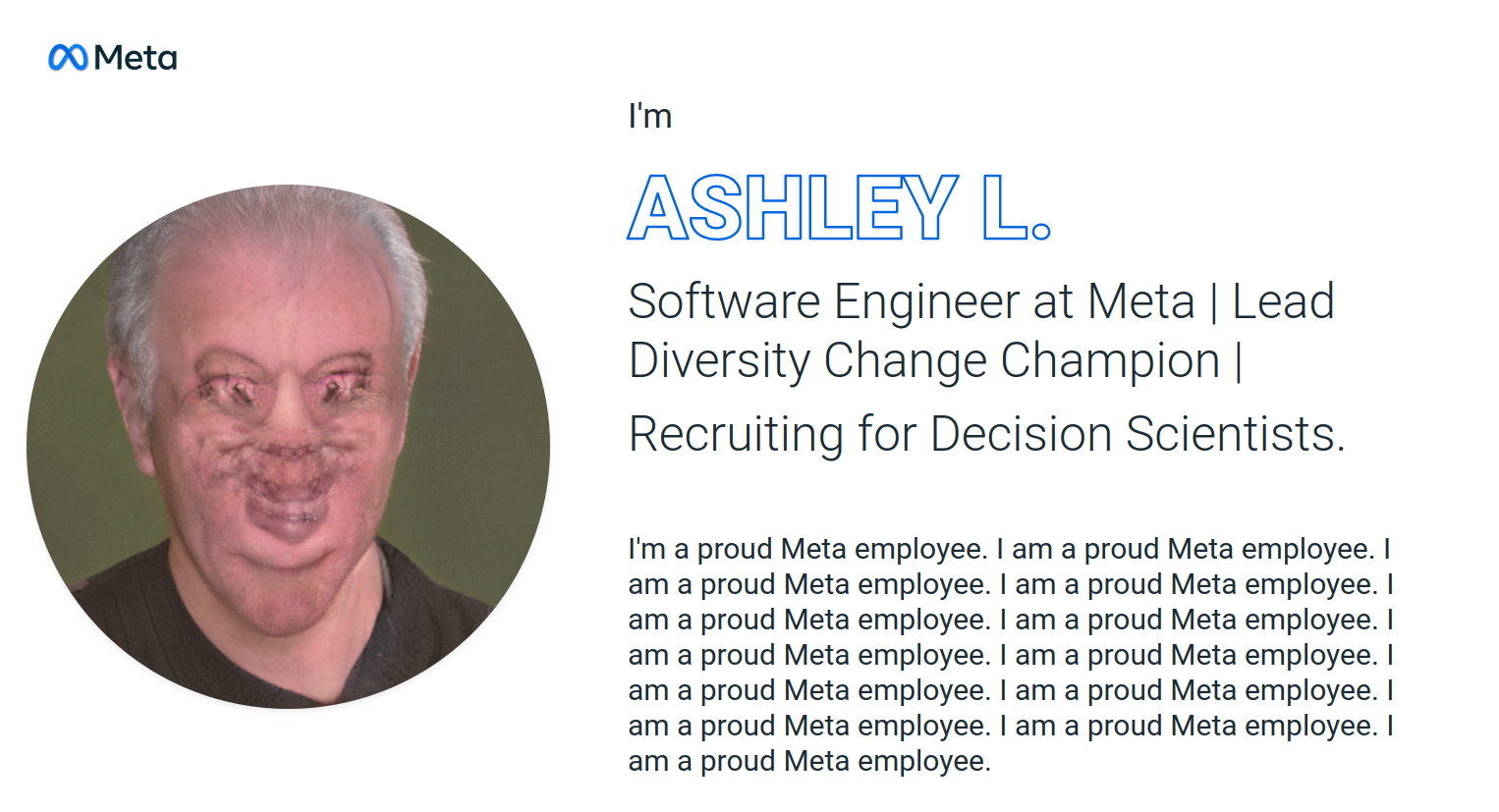
These models are, in any traditional sense, failures. But they're also working as intended. LinkedIn may be the most cursed instance of it, but we're all overfitting ourselves whenever we interact with algorithmic culture. We give our data to an algorithm that flattens us into lower dimensions to better predict our behavior, and modify that behavior to better perform on that same algorithm. The loop goes on, and on, and on.
These models are just an acceleration of processes that are already in place. The ideal outcome of a machine-learning driven society is overfitting: a world where, whether all our jobs are automated or we've just trained ourselves to work with the machine, no new information will need to be processed, all will be determined and predicted.
We're already in the Demon Zone. We just don't know it yet.